머신러닝은 현대 AI의 핵심으로, 추천 시스템부터 자율주행 자동차까지 모든 것을 구동합니다. 하지만 모든 지능형 애플리케이션의 이면에는 이 모든 것을 가능하게 하는 기반 모델이 있습니다. 이 글에서는 핵심 머신러닝 모델을 간결하면서도 포괄적으로 분석합니다.
선형 회귀
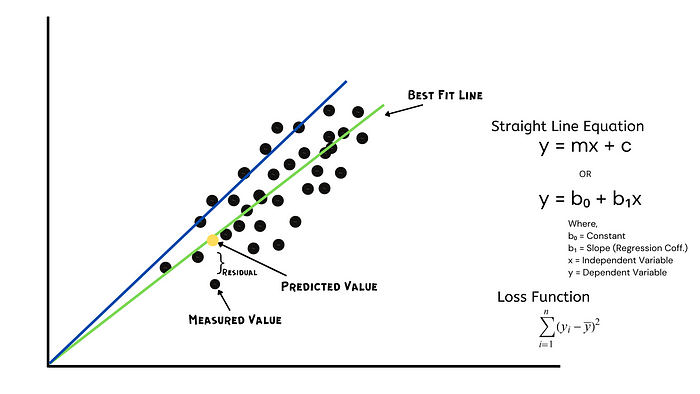
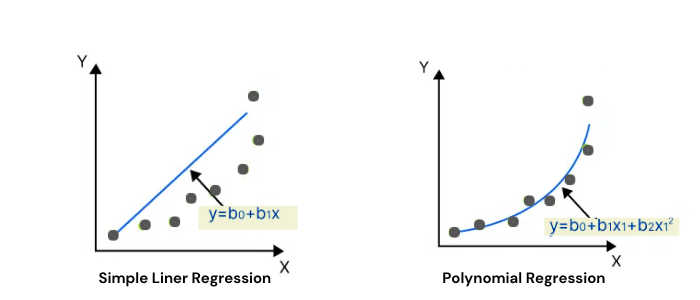
선형 회귀 분석은 최소제곱법을 사용하여 모든 데이터 지점으로부터 최소 거리를 갖는 ” 최적 적합선 ” 을 찾아 독립 변수와 종속 변수 간의 관계를 구합니다 . 최소제곱법은 잔차 제곱합(SSR)을 최소화하는 선형 방정식을 찾습니다.
예를 들어, 아래의 녹색 선은 모든 데이터 포인트와의 거리가 최소이기 때문에 파란색 선보다 더 잘 맞습니다.
라소 회귀(L1)
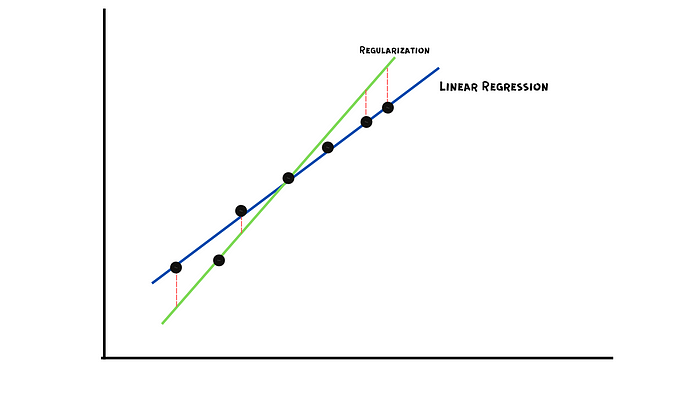
라소 회귀는 모델에 어느 정도의 편향을 도입하여 과적합을 줄이는 정규화 기법입니다. 이는 잔차의 제곱 차이에 페널티를 추가하여 최소화하는 방식입니다. 페널티는 기울기의 절댓값에 람다를 곱한 값과 같습니다. 람다는 페널티의 심각도를 나타냅니다. 과적합을 줄이고 더 나은 적합도를 생성하기 위해 변경할 수 있는 하이퍼파라미터 역할을 합니다.
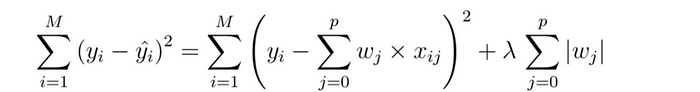
L1 정규화는 기울기 값이 훨씬 작은 모든 변수를 무시하기 때문에 많은 수의 특성이 있는 경우 선호되는 선택입니다.
릿지 회귀(L2)
릿지 회귀는 라소 회귀와 유사합니다. 두 회귀의 유일한 차이점은 페널티 항의 계산 방식입니다. 릿지 회귀는 람다 크기의 제곱에 해당하는 페널티 항을 추가합니다.
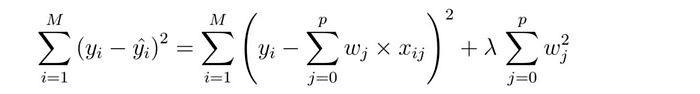
L2 정규화는 다중공선성( 독립 변수 간의 상관관계가 높음 ) 이 있는 데이터에 문제가 있을 때 사용하는 것이 가장 좋습니다. 이 정규화는 모든 계수를 0에 가깝게 줄여주기 때문입니다.
탄성 네트 회귀
탄력적 네트워크 회귀는 라쏘 회귀와 릿지 회귀의 페널티를 결합하여 보다 정규화된 모델을 제공합니다.
이 방법을 사용하면 두 가지 페널티의 균형을 맞출 수 있어 l1 또는 l2만 사용하는 경우에 비해 모델 성능이 더 뛰어납니다.
다항식 회귀
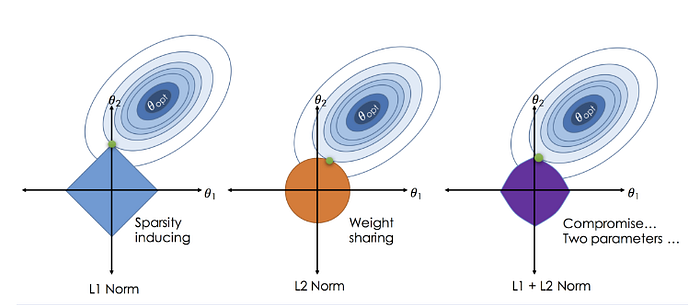
종속변수와 독립변수 간의 관계를 nᵗʰ 차수 다항식으로 모델링합니다. 다항식은 kⁿ 형태의 항들의 합으로 , n 은 음이 아닌 정수, k 는 상수, x는 독립변수입니다. 비선형 데이터에 사용됩니다.
로지스틱 회귀
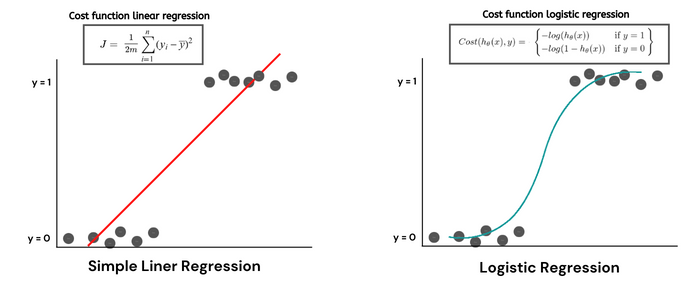
로지스틱 회귀는 데이터에 가장 적합한 곡선을 찾는 분류 기법입니다. 시그모이드 함수를 사용하여 출력을 0과 1 사이의 범위로 변환합니다. 최소제곱법을 사용하여 가장 적합한 직선을 찾는 선형 회귀와 달리, 로지스틱 회귀는 최대우도추정(MLE)을 사용하여 가장 적합한 직선(곡선)을 찾습니다.
K-최근접 이웃(KNN)
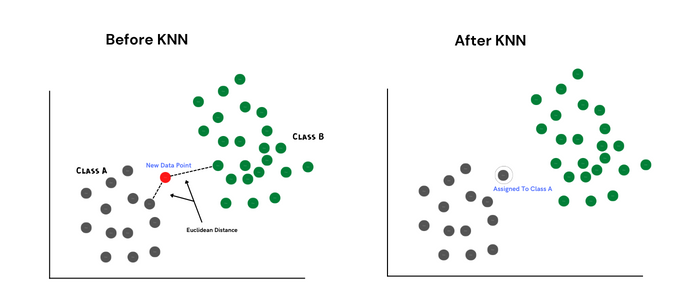
KNN은 가장 가까운 분류 지점과의 거리를 기준으로 새로운 데이터 지점을 분류하는 분류 알고리즘입니다. 서로 가까운 거리에 있는 데이터 지점들은 매우 유사하다고 가정합니다.
KNN 알고리즘은 학습 데이터를 저장하고 예측을 위한 새로운 데이터 포인트가 발생할 때까지 다른 클래스로 분류하지 않기 때문에 게으른 학습자라고도 합니다.
기본적으로 KNN은 유클리드 거리를 사용하여 새 데이터에 대한 가장 가까운 분류된 포인트를 찾고, 가장 가까운 클래스 모드를 사용하여 새 데이터 포인트에 대한 예측 클래스를 찾습니다.
k 값이 낮게 설정되면 새로운 데이터 포인트가 이상치로 간주될 수 있습니다. 그러나 값이 너무 높으면 샘플이 적은 클래스를 간과할 수 있습니다.
나이브 베이즈
나이브 베이즈는 베이즈 정리에 기반한 분류 기법으로, 주로 텍스트 분류에 사용됩니다.
베이즈 정리는 사건과 관련될 수 있는 조건에 대한 사전 지식을 바탕으로 사건의 확률을 설명합니다. 베이즈 정리는 다음과 같은 방정식을 제시합니다.
나이브 베이즈는 특정 특징의 발생이 다른 특징의 발생과 독립적이라고 가정하기 때문에 나이브 베이즈라고 불립니다.
지원 벡터 머신
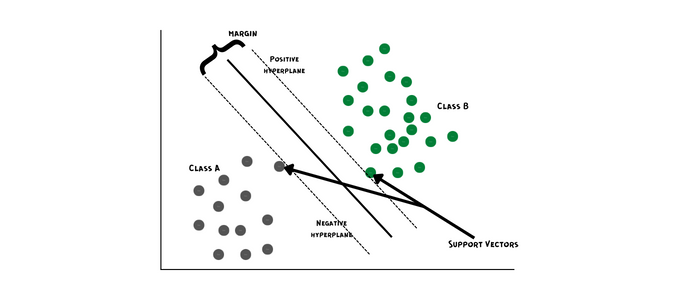
서포트 벡터 머신의 목표는 n차원 공간(n개의 특징)에서 데이터 포인트를 여러 클래스로 구분할 수 있는 초평면을 찾는 것입니다. 초평면은 클래스 간 거리(margin)를 최대화하여 찾습니다.
지원 벡터는 초평면에 대한 닫힌 데이터 포인트로, 초평면의 위치와 방향에 영향을 미치고 클래스 간 마진을 극대화하는 데 도움이 될 수 있습니다. 초평면의 차원은 입력 특성의 수에 따라 달라집니다.
의사결정 트리
의사결정 트리는 샘플이 바닥에 도달할 때까지 어떤 경로를 취할지 결정하는 일련의 조건문을 포함하는 트리 기반 구조 분류기입니다.
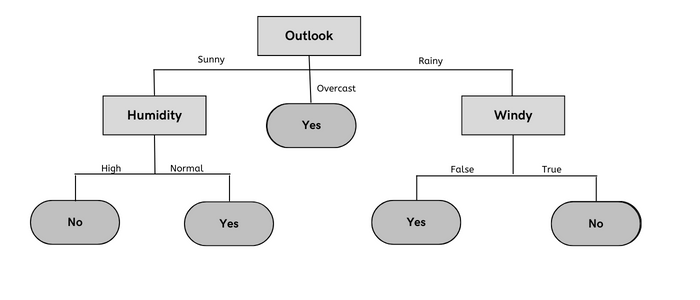
의사결정 트리의 내부 노드는 특징을, 가지는 의사결정 규칙을, 잎 노드는 결과를 나타냅니다. 트리의 의사결정 노드는 if-else 조건처럼 작동하며, 잎 노드는 의사결정 노드의 출력을 포함합니다.
먼저 속성 선택 측정(ID3 또는 CART)을 사용하여 속성을 루트 노드로 선택한 다음, 나머지 속성을 부모 노드와 재귀적으로 비교하여 트리가 리프 노드에 도달할 때까지 자식 노드를 생성합니다.
CART(GINI)
1. 확률표
2. 흐림, 맑음, 비와 같은 속성 값에 대한 지니 지수를 계산합니다
.1 - (P/P+N)² -(N/P+N)²
3. 속성에 대한 지니 지수를 계산합니다.예: Outlook
len(sunny) / len(y) *gini(sunny) + ....
ID3(정보 이득 및 엔트로피)
1. y에 대한 IG를 계산합니다
.IG(Attr) = -[P/P+N] * log[p/P+N] - [N/P+N * log[N/P+N]
2. outlook - overcase,rain,sunny와 같은 다른 속성의 각 값에 대한 엔트로피를 계산합니다.
엔트로피(Attr=Value) = -[P/P+N] * log[p/P+N] - [N/P+N * log[N/P+N]
3. 다음과 같은 속성에 대한 이득을 계산합니다. outlook
Gain(Outlook) = len(sunny) / len(y) *entropy(sunny) + ....
4. 총 정보 이득
IG(y) - 이득(속성)
IG(결과) - 이득(Outlook) 계산
랜덤 포레스트
랜덤 포레스트는 여러 개의 의사결정 트리로 구성된 앙상블 기법입니다. 각 트리를 구축할 때 배깅과 특징 무작위성을 사용하여 상관관계가 없는 의사결정 트리들의 숲을 형성합니다.
랜덤 포레스트 내부의 각 트리는 결과를 예측하기 위해 다른 데이터 하위 집합을 사용하여 학습한 다음, 다수 득표를 얻은 결과를 랜덤 포레스트 예측으로 선택합니다.
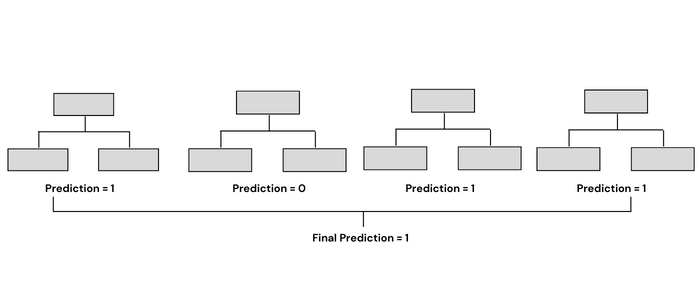
예를 들어, 두 번째 의사결정 트리를 하나만 만들었다면 예측은 클래스 0이 되지만, 네 개 트리의 모드에 따라 예측은 클래스 1로 바뀌었습니다. 이것이 랜덤 포레스트의 힘입니다.
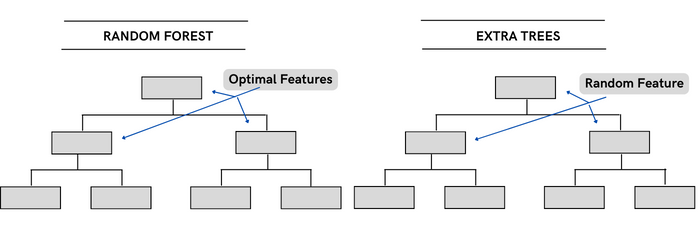
Extra Trees
Extra Trees는 랜덤 포레스트 분류기와 매우 유사하지만, 두 분류기의 유일한 차이점은 루트 노드를 선택하는 방식입니다. 랜덤 포레스트에서는 최적의 특징을 사용하여 분할하는 반면, Extra Tree 분류기에서는 무작위 특징을 선택하여 분할합니다 . Extra Tree는 더 높은 무작위성을 제공하고 특징 간의 상관관계는 매우 낮습니다.
두 가지를 비교하는 또 다른 점은 랜덤 포레스트가 앙상블 멤버(의사결정 트리)를 훈련하기 위해 크기 N의 하위 집합을 생성하는 데 부트스트랩 복제본을 사용하는 반면, 추가 트리는 전체 원본 샘플을 사용한다는 것입니다.
추가 트리 알고리즘은 랜덤 포레스트에 비해 계산 속도가 훨씬 빠릅니다. 각 결정 트리가 분할 지점을 무작위로 선택한다는 점을 고려하면 학습부터 예측까지의 전체 절차가 동일하기 때문입니다.
ADA 부스트
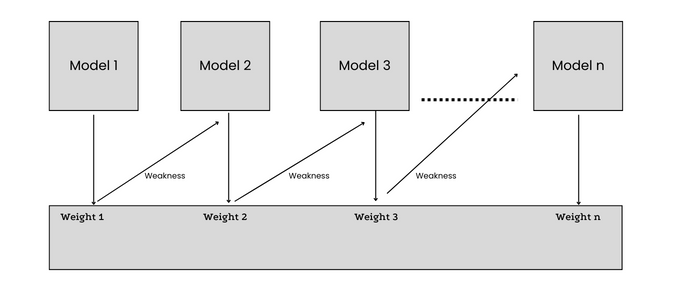
ADA Boost는 Random Forest와 유사한 부스팅 알고리즘이지만 몇 가지 중요한 차이점이 있습니다.
- ADA Boost는 의사결정 트리의 숲을 구축하는 대신 의사결정 스텀프의 숲을 만듭니다. (스텀프는 노드가 하나이고 리프가 두 개인 의사결정 트리입니다.)
- 각 결정 단위에는 최종 결정에서 서로 다른 가중치가 지정됩니다.
- 잘못 분류된 데이터 포인트에 더 높은 가중치를 할당하여 다음 모델을 구축할 때 해당 데이터 포인트의 중요성을 높입니다.
- 여러 개의 “약한 분류기”를 하나의 강력한 분류기로 결합하는 데 도움이 됩니다.
그래디언트 부스팅
그래디언트 부스팅은 각 트리가 이전 트리의 실수로부터 학습하는 여러 개의 의사결정 트리를 구축합니다. 잔차 오차를 활용하여 예측 성능을 향상시킵니다. 그래디언트 부스팅의 궁극적인 목표는 잔차 오차를 최대한 줄이는 것입니다.
그래디언트 부스팅은 ADA 부스트와 비슷하지만, 두 가지의 차이점은 ADA 부스트는 의사결정 스텀프를 구축하는 반면 그래디언트 부스팅은 여러 개의 리프로 의사결정 트리를 구축한다는 것입니다.
그래디언트 부스팅은 기본 의사결정 트리를 구축하고 초기 예측값(보통 평균값)을 구하는 것으로 시작합니다. 그런 다음, 초기 특성과 잔차 오차를 종속 변수로 하는 새로운 의사결정 트리를 생성합니다. 새로운 의사결정 트리에 대한 예측은 모델의 초기 예측값 + 샘플의 잔차 오차 + 학습률을 곱한 값을 사용하며, 이 과정은 최소 오차에 도달할 때까지 반복됩니다.
K-평균 클러스터링
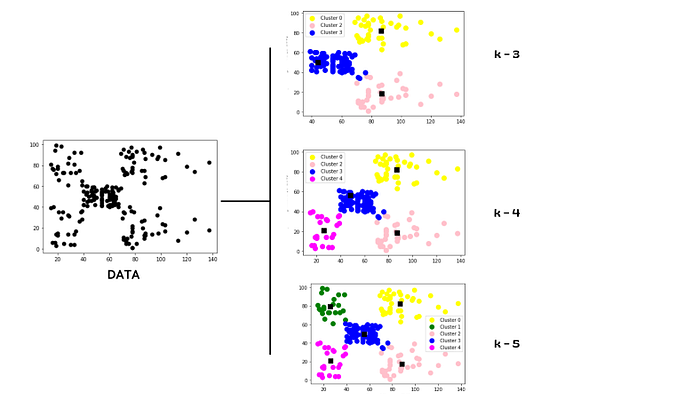
KMeans 클러스터링은 레이블이 지정되지 않은 데이터를 K개의 서로 다른 클러스터로 그룹화하는 비지도 머신 러닝 알고리즘입니다. 여기서 K는 사용자가 정의한 정수입니다.
이는 클러스터 중심을 사용하여 레이블이 지정되지 않은 데이터를 K개의 클러스터로 나누어 유사한 속성을 가진 데이터 포인트가 동일한 클러스터에 속하도록 하는 반복 알고리즘입니다.
1. K를 정의하고 K 클러스터를 생성합니다
. 2. K 중심에서 각 데이터 포인트의 유클리드 거리를 계산합니다
. 3. 중심에 가장 가까운 데이터 포인트를 지정하고 클러스터를 생성합니다.
4. 평균을 취하여 중심을 다시 계산합니다.
계층적 클러스터링
계층적 클러스터링은 데이터를 트리 형태로 계층적으로 분할하는 클러스터링 기반 알고리즘의 또 다른 유형입니다. 데이터 간의 관계를 자동으로 파악하고 이를 n개의 서로 다른 클러스터로 분할합니다. 여기서 n은 데이터 크기입니다.
계층적 클러스터링에는 집적적 접근 방식과 분할적 접근 방식의 두 가지 주요 접근 방식이 있습니다.
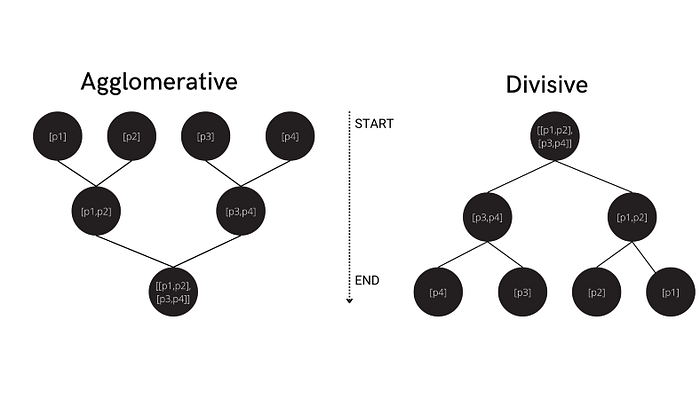
응집형 군집화에서는 각 데이터 포인트를 하나의 군집으로 간주한 후, 하나의 그룹(전체 데이터 세트)이 될 때까지 이 군집들을 결합합니다. 반면, 분할형 계층형 군집화는 전체 데이터 세트(하나의 군집으로 간주)에서 시작하여, 각 개별 데이터 포인트가 고유한 군집을 형성할 때까지 덜 유사한 군집으로 분할합니다.
DBSCAN 클러스터링
DBSCAN (노이즈가 있는 애플리케이션의 밀도 기반 공간 클러스터링)은 데이터 포인트가 단일 포인트가 아닌 클러스터의 여러 데이터 포인트 에 가까울 경우 해당 데이터 포인트가 클러스터에 속한다고 가정합니다 .
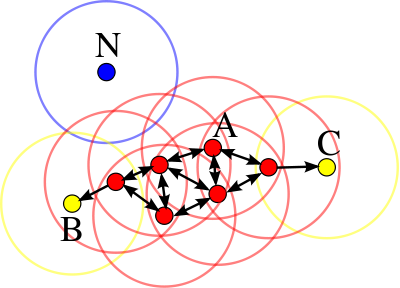
epsilon그리고 min_points는 데이터를 작은 클러스터로 나누는 데 유용한 두 가지 중요한 매개변수입니다. 클러스터를 형성하는 데 필요한 최소 데이터 포인트 수를 결정할 epsilon때, 클러스터의 일부로 간주하기 위해 한 포인트가 다른 포인트와 얼마나 가까워야 하는지 지정합니다 .min_points
아프리오리 알고리즘
Apriori 알고리즘은 데이터 항목을 서로의 종속성에 따라 매핑하는 연관 규칙 마이닝 알고리즘입니다.
선험적 알고리즘을 사용하여 연관 규칙을 생성하는 몇 가지 핵심 단계는 다음과 같습니다.
1. 크기가 1인 각 항목 집합에 대한 지지도를 결정합니다. 여기서 지지도는 데이터 집합 내 항목의 빈도입니다.
2. 최소 지지도 임계값(사용자가 결정)보다 낮은 모든 항목을 탐색합니다.
3. 크기가 n+1인 항목 집합(n은 이전 항목 집합 크기)을 생성하고 모든 항목 집합 지지도가 임계값을 초과할 때까지 1단계와 2단계를 반복합니다.
4. 신뢰도(x의 발생 빈도가 이미 주어졌을 때 x와 y가 함께 발생하는 빈도)를 사용하여 규칙을 생성합니다.
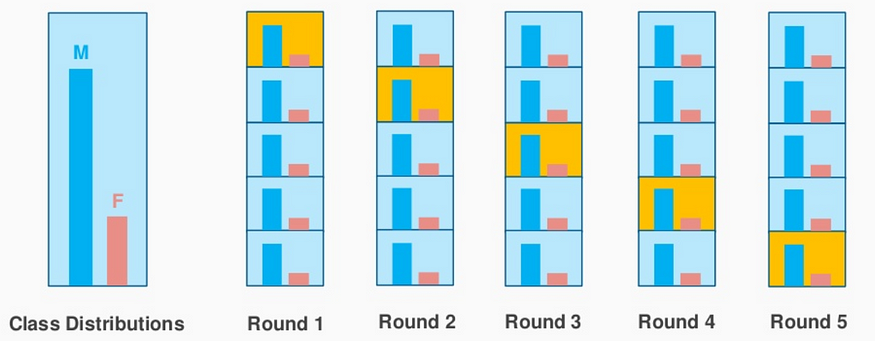
계층화된 K-폴드 교차 검증
층화 K-겹 교차 검증은 무작위 표집 대신 층화 표집법을 사용하여 데이터의 부분집합을 생성하는 K-겹 교차 검증의 변형입니다. 층화 표집법에서는 데이터를 전체 데이터 집합의 분포와 유사한 분포를 갖는 K개의 서로 겹치지 않는 그룹 으로 나눕니다 . 각 부분집합은 아래 그림과 같이 각 클래스 레이블에 대해 동일한 개수의 값을 갖습니다.
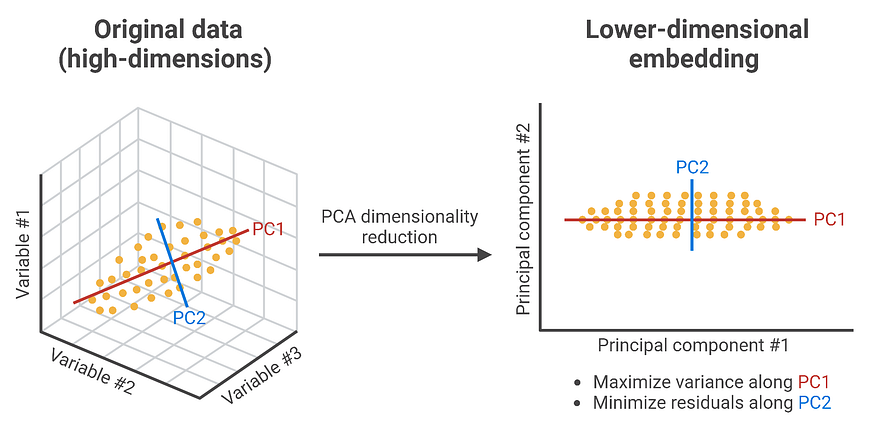
주성분 분석
PCA는 상관관계가 있는 특징 집합을 더 적은 수( k<p )의 상관관계가 없는 특징, 즉 주성분으로 변환하는 선형 차원 축소 기법입니다. PCA를 적용하면 일부 정보는 손실되지만, 모델 성능 향상, 하드웨어 요구 사항 감소, 시각화를 통한 데이터 이해 개선 등 여러 가지 이점을 제공합니다.
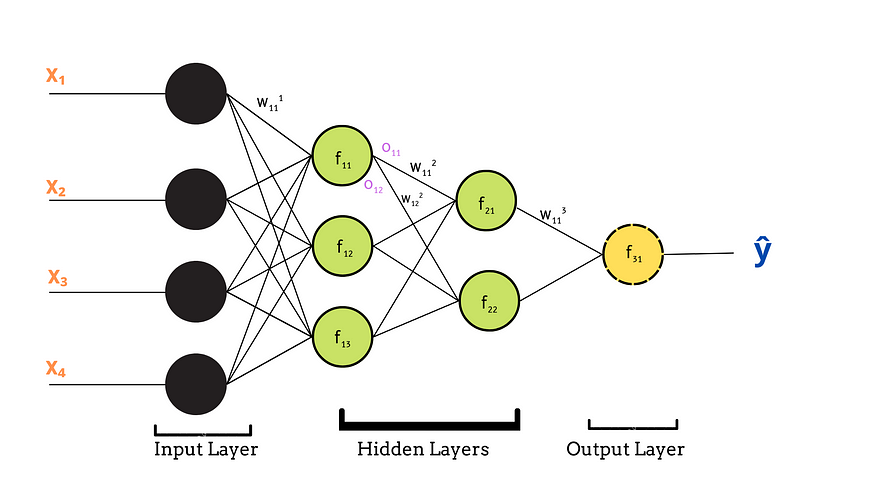
인공 신경망(ANN)
인공 신경망(ANN)은 상호 연결된 뉴런 층으로 구성된 인간 뇌의 구조에서 영감을 받았습니다. ANN은 입력층, 은닉층, 출력층 으로 구성되며 , 각 뉴런은 입력 데이터에 가중치와 활성화 함수를 적용합니다. ANN은 데이터에서 복잡한 패턴을 학습할 수 있기 때문에 이미지 인식, 자연어 처리, 예측 분석 등의 작업에 널리 사용됩니다.
합성곱 신경망(CNN)
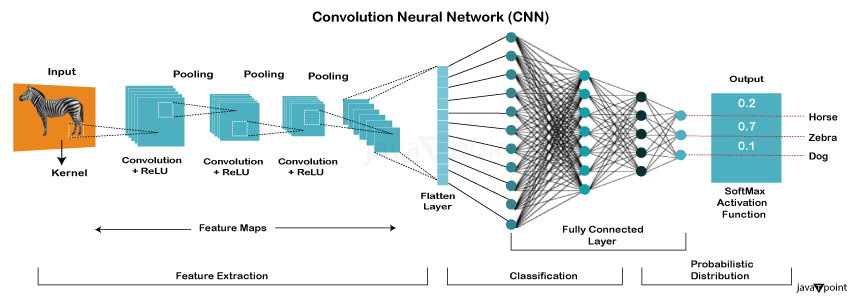
합성곱 신경망(CNN)은 주로 이미지 및 비디오 처리를 위해 설계된 특수한 유형의 신경망입니다 . 각 픽셀을 별도의 입력으로 처리하는 기존 신경망과 달리, CNN은 합성곱 계층을 사용하여 이미지를 스캔하고 경계선, 질감, 모양과 같은 패턴을 감지합니다. 따라서 이미지 속 객체가 서로 다른 위치에 있더라도 매우 효과적으로 인식할 수 있습니다. CNN은 시각 데이터의 패턴을 자동으로 식별하는 방법을 학습하여 얼굴 인식, 자율주행차, 의료 영상 분석과 같은 기술을 지원합니다.
Q-러닝
Q-러닝은 기계가 시행착오를 통해 학습하도록 돕는 강화 학습 알고리즘 입니다. 게임 AI, 로봇 공학, 그리고 자가 학습 트레이딩 봇 에 널리 사용됩니다 . 아이디어는 간단합니다. 로봇이나 게임 캐릭터와 같은 “에이전트”가 환경과 상호 작용하고 다양한 행동을 시도하며, 선택에 따라 보상이나 페널티를 받습니다. 시간이 지남에 따라 학습한 내용을 Q-테이블 이라는 것에 저장하여 다양한 상황에서 취할 수 있는 최선의 행동을 학습합니다. 이 기술은 자율 주행 자동차가 교통 상황을 탐색하거나 AI 기반 게임 캐릭터가 체스를 두는 방법을 학습하는 것처럼 자율적으로 결정을 내려야 하는 AI 시스템에서 널리 사용됩니다.
용어 빈도-역문서 빈도
TF-IDF는 문서에서 중요한 단어를 식별하는 데 도움이 되는 텍스트 분석 알고리즘 입니다. 단어의 출현 빈도(용어 빈도, TF)를 계산 하고 , 이를 전체 문서에서 해당 단어가 얼마나 드문지(역문서 빈도, IDF) 와 비교합니다. 이를 통해 “the”나 “is”와 같은 흔한 단어가 높은 순위를 차지하는 것을 방지하고, 더 의미 있는 단어를 강조합니다. TF-IDF는 검색 엔진(Google, Bing), 키워드 추출 및 문서 순위 지정 에 널리 사용되어 시스템이 특정 주제와 가장 관련성이 높은 단어를 파악하는 데 도움을 줍니다.
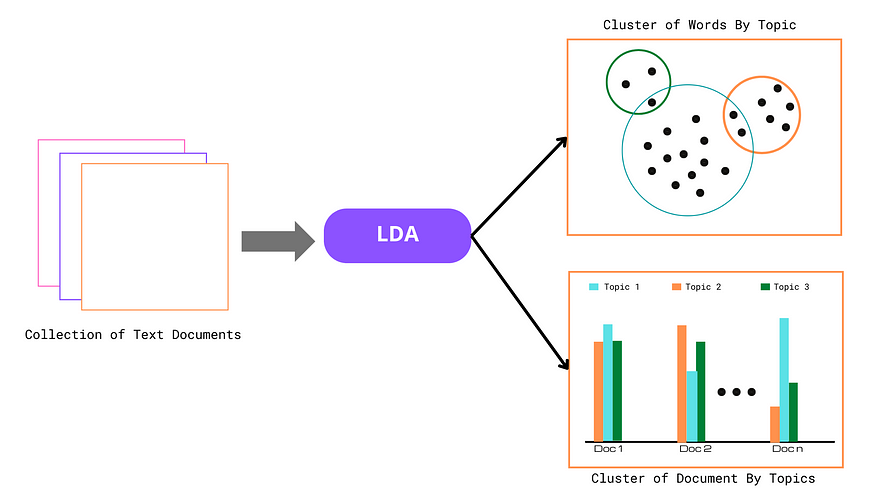
잠재 디리클레 할당(LDA)
잠재 디리클레 할당(LDA)은 방대한 텍스트에서 숨겨진 주제를 찾는 데 사용되는 주제 모델링 알고리즘 입니다. 각 문서가 서로 다른 주제로 구성되어 있으며, 각 주제는 자주 함께 등장하는 특정 단어들로 구성되어 있다고 가정합니다. LDA는 방대한 비정형 텍스트에서 숨겨진 주제를 파악하는 데 도움이 되므로 뉴스 분류, 연구 논문 분류, 고객 리뷰 분석 에 특히 유용합니다 . 연구 도구에서 자동 주제 제안 기능을 본 적이 있다면, 유사한 텍스트를 그룹화하기 위해 LDA를 사용하고 있을 가능성이 높습니다.
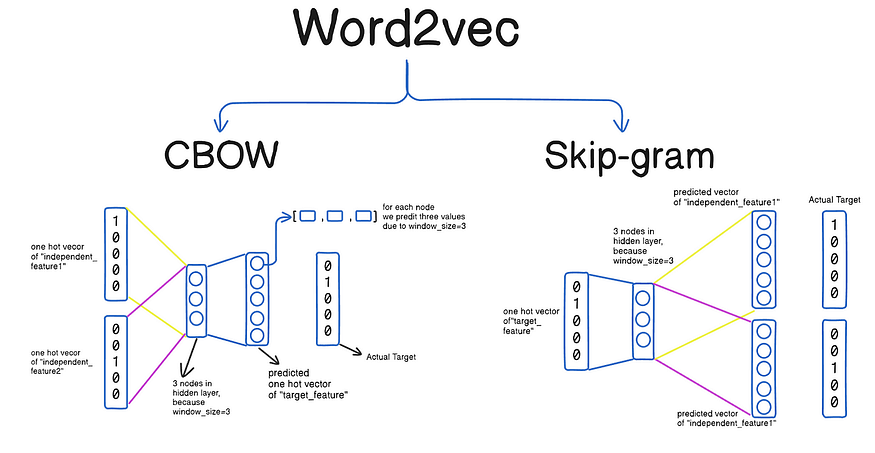
Word2Vec
Word2Vec은 컴퓨터가 단어를 수치 벡터로 변환하여 의미를 이해하도록 돕는 자연어 처리 알고리즘 입니다. 단어 빈도만 고려하는 TF-IDF와 같은 기존 방식과 달리, Word2Vec은 단어 간의 의미적 관계를 포착합니다. 예를 들어, “king”과 “queen”의 연관성을 학습하거나 , “Paris”와 “France”의 관계는 “Berlin”과 “Germany”의 관계와 같다는 것을 학습할 수 있습니다 . 이러한 특징은 단어의 의미와 맥락을 이해하는 것이 중요한 챗봇, 감정 분석, 추천 시스템 에서 매우 유용합니다 . Google Translate 및 음성 비서에 사용되는 모델을 포함한 많은 최신 언어 모델은 더 깊은 언어 이해를 위한 기반으로 Word2Vec을 활용합니다.