손실함수는 인공지능 및 머신러닝 모델의 성능 평가와 최적화에 핵심적인 역할을 합니다. 손실함수는 모델의 예측값과 실제값 간의 차이를 수치화하여 모델의 학습과 성능을 개선하는 데 사용됩니다. 다양한 손실함수가 있으며, 그 선택에 따라 모델의 학습 과정과 최종 성능이 크게 달라질 수 있습니다. 최근 연구는 수학적 이론과 실제 응용 간의 간극을 좁히고 새로운 수학적 도구를 개발하여 AI 모델의 성능을 향상시키고 있습니다.
인공지능(AI)과 수학은 불가분의 관계를 가지고 있습니다. AI 시스템의 근간을 이루는 알고리즘과 모델들은 고도의 수학적 개념과 이론에 기반을 두고 있습니다. 특히, 선형대수학, 미적분학, 확률론, 통계학 등은 AI 개발에 필수적인 수학 분야입니다. 그 중에서 손실함수 관련 최근 Nature 논문을 소개하고, 전반적인 손실함수의 기초적인 내용을 정리해 봅니다.
AI 연구의 선구자인 Alan Turing은 그의 논문 “Computing Machinery and Intelligence”(1950)에서 이미 기계의 지능을 수학적으로 정의하고 평가하는 방법을 제안했습니다. 이는 AI와 수학의 깊은 연관성을 보여주는 초기 사례입니다.
현대 머신러닝 알고리즘들, 예를 들어 신경망, 서포트 벡터 머신, 결정 트리 등은 모두 복잡한 수학적 모델을 기반으로 합니다. 2015년 발표된 “Deep Learning” (LeCun, Bengio, Hinton, Nature)는 딥러닝의 수학적 기초와 그 응용에 대해 상세히 설명하며, AI 발전에 있어 수학의 중요성을 강조했습니다.
또한 최근 AI 연구에서는 수학적 이론과 실제 응용 사이의 간극을 좁히려는 노력이 진행되고 있습니다. 예를 들어, “Reconciling modern machine learning practice and the bias-variance trade-off” (Belkin et al., 2019, PNAS)와 같은 연구는 기존의 수학적 이론과 실제 딥러닝 모델의 성능 사이의 불일치를 해결하려 시도합니다.
AI의 발전은 새로운 수학적 도구와 이론의 개발로 이어지기도 합니다. 예를 들어, 위상수학의 한 분야인 퍼시스턴트 호몰로지 이론이 데이터 분석과 기계학습에 적용되면서 새로운 연구 영역이 열리고 있습니다 (Carlsson, 2009, Bulletin of the American Mathematical Society).
손실함수의 중요성
손실함수(Loss Function)는 AI, 특히 머신러닝과 딥러닝 분야에서 핵심적인 역할을 합니다. 손실함수는 모델의 예측과 실제 값 사이의 차이를 수치화하여 모델의 성능을 평가하고 개선하는 데 사용됩니다.
Vapnik의 “The Nature of Statistical Learning Theory” (1995)에서는 손실함수의 개념과 그 중요성에 대해 깊이 있게 다루고 있습니다. 이 책은 통계적 학습 이론의 기초를 제공하며, 손실함수가 어떻게 학습 알고리즘의 성능과 일반화 능력에 영향을 미치는지 설명합니다.
손실함수의 선택은 모델의 학습 과정과 최종 성능에 큰 영향을 미칩니다. 2018년 발표된 “Visualizing the Loss Landscape of Neural Nets” (Li et al., NeurIPS)는 다양한 손실함수가 신경망의 학습 과정에 어떤 영향을 미치는지 시각적으로 보여주었습니다.
최근에는 강화학습 분야에서도 손실함수의 중요성이 부각되고 있습니다. “Prioritized Experience Replay” (Schaul et al., 2015, ICLR)에서는 손실함수를 기반으로 학습 데이터의 중요도를 평가하고 우선순위를 정하는 방법을 제안했습니다.
손실함수는 또한 AI 모델의 해석 가능성과도 관련이 있습니다. “Why Should I Trust You?: Explaining the Predictions of Any Classifier” (Ribeiro et al., 2016, KDD)에서는 손실함수를 활용하여 모델의 예측을 설명하는 방법을 제시했습니다.
이처럼 손실함수는 AI 시스템의 성능 평가, 학습 과정 최적화, 모델 해석 등 다양한 측면에서 중요한 역할을 합니다. 따라서 손실함수에 대한 깊이 있는 이해는 AI 연구와 개발에 있어 필수적이라고 할 수 있습니다.
AI를 구동하는 수학의 내부
손실 함수는 인공지능 모델의 알고리즘 오류를 측정하는 도구지만, 이를 수행하는 방법은 여러 가지가 있습니다. 올바른 함수를 선택하는 것이 중요한 이유는 여기에 있습니다.
사람들은 인공지능에서의 ‘바닥으로의 경쟁’을 나쁜 것으로 이야기하는 경우가 많습니다. 그러나 손실 함수를 논할 때는 이야기가 다릅니다.
손실 함수는 유용한 인공지능(AI)의 중요한 구성 요소이지만, 종종 간과되곤 합니다. 이 함수들은 그래프의 곡선에서 가능한 한 빨리 바닥, 즉 최소점에 도달하는 것을 목표로 합니다. 수백만 장의 사진에서 특정 특징을 찾는 것과 같이 반복적인 데이터 분석을 자동화하는 알고리즘을 훈련할 때, 성능을 측정하는 방법이 필요합니다. 이것이 바로 ‘손실 함수’입니다. 손실 함수는 알고리즘의 오류를 데이터의 ‘정답’에 상대적으로 측정합니다. 그런 다음 알고리즘의 매개변수를 조정하고, 다시 시도하면서 오류가 점점 줄어들기를 바랍니다. “오류가 가능한 한 작은, 이상적으로는 0이 되는 최소점을 찾으려고 노력하는 것입니다,”라고 프리토리아 대학교의 계산지능 연구원인 안나 보스만(Anna Bosman)은 말합니다.
수십 개의 기존 손실 함수가 존재합니다. 하지만 잘못된 함수를 선택하거나 잘못 다루면 알고리즘이 잘못된 방향으로 이끌 수 있습니다. 이는 인간의 관찰과 명백히 모순되거나, 실험적 노이즈(무작위 변동)를 데이터로 오인하게 만들거나, 실험의 중심 결과를 숨길 수 있습니다. “잘못될 수 있는 것이 많습니다,”라고 보스만은 말합니다. 무엇보다도, 블랙박스 형태의 AI 계산 때문에 잘못된 방향으로 인도되었음을 알지 못할 수도 있습니다.
이 때문에 점점 더 많은 과학자들이 기존 손실 함수를 버리고 직접 제작한 손실 함수를 사용하고 있습니다. 그러나 그들은 어떻게 그것을 올바르게 만들까요? 어떻게 하면 자작 손실 함수가 시간을 잡아먹는 실수가 아닌, 주요 도구가 될 수 있을까요?”
오류 평가
머신러닝 알고리즘은 일반적으로 라벨링(정답)이 달린 데이터로 훈련되거나, 정답이 틀렸을 때 알려줌으로써 훈련됩니다. 손실 함수는 이러한 틀림을 수학적으로 측정하는 도구지만, 이를 측정하는 방법은 여러 가지가 있습니다.
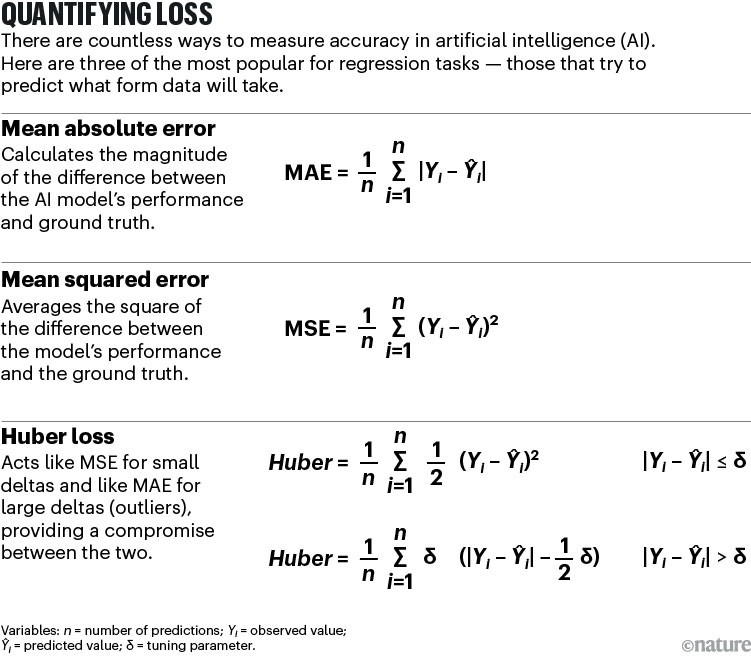
예를 들어, ‘절대 오차’ 함수는 알고리즘의 예측값과 목표값 사이의 차이를 보고합니다. 또 다른 방법으로는 평균 제곱 오차가 있습니다. 이는 예측값과 실제값 사이의 차이를 제곱한 후, 전체 데이터 세트에 걸쳐 이를 평균내는 방식입니다.
평균 제곱 오차는 간단하고 검증된 접근법으로, 오류가 비교적 작고 일관될 때 잘 작동합니다. 하지만 데이터에 이상치(outlier)가 많으면 문제가 될 수 있습니다. 왜냐하면 알고리즘이 이상치의 영향을 크게 증폭시키기 때문입니다. 이를 해결하기 위해 ‘pseudo-Hube’라는 손실 함수가 있습니다. 이는 후버 손실 함수라는 접근법을 부드럽게 근사한 것으로, 각 데이터 포인트의 오류가 큰지 작은지를 고려하여 평균 제곱 오차와 절대 오차 손실 함수 사이에서 절충점을 제공합니다.
절대 오차, 평균 제곱 오차, 후버 손실 함수는 주로 회귀 분석에 유용합니다. 회귀 분석은 키나 체중과 같은 연속 변수에 대한 과거 데이터를 사용해 미래 데이터 세트의 형태를 예측하는 데 사용됩니다. 반면, 분류 작업은 어떤 객체가 무엇인지, 데이터 세트에 몇 개 있는지와 같은 질문에 답합니다. 이 경우, 머신러닝 알고리즘은 객체가 특정 클래스에 속할 확률을 결정합니다. 예를 들어, 특정 픽셀 집합이 개를 나타낼 가능성이 얼마나 되는지를 판단하는 것입니다. 이 경우 유용한 손실 함수로는 크로스 엔트로피와 힌지 손실이 있습니다. 크로스 엔트로피는 모델의 출력과 실제 값 사이의 확률 분포를 비교하는 척도이고, 힌지 손실은 각 데이터 포인트에서 가능한 한 가장 멀리 떨어진 곡선을 찾아 데이터 포인트가 어느 카테고리에 속하는지 명확히 구분해줍니다.”
일반적인 손실 함수가 항상 최선의 선택은 아닙니다. 아르준 라즈의 경험을 예로 들어 보죠.
필라델피아에 있는 펜실베이니아 대학교의 유전학자인 라즈는 형광 현미경을 사용해 단일 세포 내의 유전자 발현을 정량화합니다. 이 실험에서는 각 RNA 전사체가 이미지의 개별 점으로 나타나며, 이 점들을 세어 올바른 세포에 할당하는 것이 중요합니다. 인간에게는 두세 픽셀 크기의 점을 찾는 것은 쉽습니다. “어느 여름에 고등학생이 저와 함께 일했는데, 그 학생에게 이미지를 완벽하게 주석 다는 방법을 2분 만에 가르칠 수 있었습니다,”라고 라즈 연구실의 전 학부생인 윌리엄 니우가 말합니다.
하지만 연구실에서는 수백만 개의 세포에서 수천 개의 형광 점을 나타내는 데이터 세트를 생성하기 때문에 수작업으로 분석하기에는 너무 많습니다. 더욱이, 이 분석은 기계에게는 인간보다 훨씬 어렵습니다. 라즈와 그의 동료들이 이 과정을 자동화하려고 시도했을 때, 알려진 손실 함수 중 어느 것도 신뢰할 만한 결과를 제공하지 못한다는 것을 발견했습니다.
문제의 주요 원인은 ‘클래스 불균형’에 있었습니다. 라즈는 이렇게 말합니다: “점이 드문드문 있을 때, 알고리즘은 모든 픽셀을 ‘점 아님’으로 레이블링하면 잘하고 있다고 생각할 수 있습니다. 하지만 이는 엄청나게 높은 거짓 음성 비율을 초래합니다.” 라즈는 “아주 ‘좋은’ 분류기를 만들 수 있는데, 이 분류기는 이미지에 점이 없다고 말하기만 합니다. 왜냐하면 99.9%의 시간 동안 실제로 점이 없기 때문입니다. 이런 분류기는 어떤 의미에서는 매우 정확하지만, 실제로는 아무 쓸모가 없습니다,”라고 말합니다.
니우와 라즈, 그리고 연구실의 다른 사람들은 이러한 문제를 해결하기 위해 SmoothF1이라는 손실 함수를 만들었습니다. F1 점수는 거짓 음성과 거짓 양성의 균형을 맞추는 지표입니다. 하지만 F1 점수의 수학적 함수는 미분할 수 없기 때문에 신경망을 훈련하는 데 사용할 수 없습니다. SmoothF1은 F1 점수를 근사하여 클래스 불균형을 보정하면서도 알고리즘이 오류 기울기의 최저점으로 갈 수 있도록 합니다. 팀은 이 함수를 사용해 Piscis라는 점 탐지 알고리즘을 만들었습니다.
니우가 한 작업은 “우리 연구실에 큰 변화를 가져왔다”고 라즈는 말합니다. “이 작업 덕분에 훨씬 더 많은 양의 분석을 할 수 있게 되었습니다.” 니우는 Piscis가 다양한 응용 분야에 유용할 것이라고 말합니다. “이론적으로, 우리 방법은 찾고자 하는 객체가 이미지의 5% 미만을 차지하는 모든 유형의 객체에서 더 나은 성능을 발휘할 수 있습니다,”라고 그는 말합니다.
매사추세츠 공과대학교(MIT)의 화학공학 학생인 페드로 세버는 포유류 단백질에서 당화 부위를 예측하기 위해 자신의 손실 함수를 만들었습니다. 당화 부위 예측은 암을 포함한 질병 경로를 이해하는 데 유용할 수 있습니다.
세버는 처음에는 머신러닝 측면에 깊이 파고들 생각이 없었습니다. 그는 교차 엔트로피 기반 손실 함수를 사용해 모델을 훈련시키려고 했지만, 이는 모델 성능을 저하시켰습니다. “때때로 교차 엔트로피가 가장 낮은 모델이 반드시 가장 좋은 지표를 가진 모델은 아니었습니다,”라고 세버는 말합니다. 더 깊이 파고들자 교차 엔트로피가 실제로 예측 작업과 관련이 없다는 것을 알게 되었습니다. “그것은 제가 실제로 신경 쓰지 않는 것을 최적화하고 있었습니다,”라고 그는 설명합니다.
세버는 자신이 신경 쓰는 것에 초점을 맞춘 맞춤형 손실 함수를 만들기로 했습니다. 이는 F1과 유사한 기능을 제공하는 매튜스 상관 계수(MCC)의 수정된 버전입니다. 세버의 ‘가중치 초점 미분 가능 MCC 손실 함수’는 MCC 성능을 약 10% 향상시켰습니다. 세버는 이것이 아주 큰 향상은 아니지만, “이 시점에서는 모든 향상이 중요합니다”라고 말합니다. 세버는 이 향상 덕분에 최첨단 성능을 달성할 수 있었고, 이는 약물 및 생물 치료제 개발을 위한 잠재적 표적인 당화 부위를 예측하는 데 매우 바람직한 결과라고 말합니다.
워싱턴 리치랜드에 있는 태평양 북서부 국립 연구소의 데이터 과학자인 앤드류 엥겔은 손실 함수를 만드는 모든 시도가 큰 성공을 거두지는 않을 것이라고 경고합니다. 엥겔은 예를 들어, 망원경 이미지에서 은하의 적색편이를 평가하는 데 도움을 주기 위해 설계된 손실 함수로 혼합된 결과를 얻었습니다. 적색편이는 지구에서 객체의 거리를 유도하는 데 사용되는 측정값입니다.
엥겔은 기존 손실 함수에 천문학적 지식을 추가하면 성능이 향상될 수 있을지 궁금했습니다. 놀랍게도, 그렇지 않았습니다. 아마도 알고리즘에 제공한 새로운 정보가 이미 알고 있던 것을 반복하는 것에 불과했기 때문입니다. 하지만 시간을 낭비하지는 않았습니다. 모델 훈련은 특히 시간이 많이 걸리지 않았기 때문에 다양한 접근 방식을 테스트할 수 있었습니다. 엥겔은 “이 분야의 좋은 점은 우리의 아이디어가 작동하는지 여부에 대한 지속적인 피드백을 받을 수 있다는 것입니다,”라고 말합니다.
무엇을 측정해야 할까?
그렇다고 해서 연구자들이 항상 손실 함수가 무엇을 측정해야 하는지 명확히 말할 수 있는 것은 아닙니다. AI가 더 잘하기를 바라지만, 어떤 방식으로 더 잘해야 할까요? “당신이 원하는 것을 수학적으로 표현하는 데에는 항상 장벽이 있을 것입니다,”라고 니우는 말합니다.
이 관점은 콜럼버스에 있는 오하이오 주립대학교의 공학 연구원인 한솔 류와 마노즈 스리니바산이 2023년에 발표한 연구에 의해 뒷받침됩니다. 류와 스리니바산은 과학자와 엔지니어들에게 다양한 데이터 세트에 곡선을 맞추는 작업을 수작업으로 수행하도록 요청했습니다. 팀은 놀랍게도 각 개인의 접근 방식이 데이터 세트마다, 그리고 사람마다 다르다는 것을 발견했습니다.
“사람들은 컴퓨터 알고리즘보다 훨씬 더 변동성이 큽니다,”라고 류는 말합니다. 예를 들어, 평균 제곱 오차를 시각화하려고 한다고 말한 많은 사람들이 무의식적으로 다른 방법을 사용하고 있었습니다. 그 방법은 평균이 아닌 데이터 세트의 최빈값을 찾는 것이었습니다. 또한, 연구자들은 이상치를 처리하는 방식에서도 일관성이 없었고, 데이터 양이 증가할수록 이상치를 더 많이 배제하는 경향이 있었습니다.
상황을 더 복잡하게 만드는 것은 AI를 훈련시키는 것이 단순히 오류를 최소화하는 것 이상의 문제라는 점입니다. 연구자들은 ‘과적합’을 피해야 합니다. 과적합은 모델이 현실 세계의 데이터와 작동할 수 없을 정도로 너무 좁게 훈련된 상태를 의미합니다. 즉, 손실 함수가 매우 효율적이지만 좋은 방식은 아닙니다. “모델이 너무 복잡하면 데이터 세트의 모든 점을 지나는 매우 복잡한 함수가 될 수 있습니다,”라고 보스만은 말합니다. “이론상으로는 모델이 매우 훌륭해 보이지만, 실제 데이터에 적용해 보면 결과가 끔찍하고 예측이 완전히 잘못될 것입니다.”
그러나 보스만의 주요 조언은 ‘노이즈를 알아라’입니다. “현실 세계의 데이터는 매우, 매우 혼란스럽습니다,”라고 그녀는 지적합니다. 일반적인 손실 함수는 가정을 합니다. 하지만 이 가정이 반드시 당신의 데이터에 적용되는 것은 아닙니다. 예를 들어, 회귀 문제에 가장 일반적으로 사용되는 손실 함수인 평균 제곱 오차는 데이터 포인트의 정규 분포를 가정합니다. 그러나 당신의 데이터는 다른 형태에 더 잘 맞을 수도 있습니다. 보스만은 이러한 데이터를 위해 코시 분포를 사용하는 손실 함수를 연구한 팀의 일원입니다. 이 분포는 정규 분포와 유사하지만 꼬리가 더 두꺼운 특징이 있습니다. 즉, 더 많은 데이터가 가장 흔한 값 외부에 위치합니다. 코시 기반 손실 함수는 데이터가 정규 분포에 맞지 않는 노이즈가 있을 때 더 나은 성능을 발휘할 수 있습니다,”라고 그녀는 말합니다.
함수를 선택하세요
이런 고려 사항의 중요성을 과소평가할 수는 없다고 브리즈번, 호주에 있는 퀸즐랜드 대학교의 머신러닝 대학원생인 조나단 윌튼이 말합니다. “데이터에 오류나 문제가 있을 가능성이 있다고 생각된다면, 표준적인 손실 함수가 아닌 다른 손실 함수를 사용하는 것이 좋을 것입니다,”라고 그는 말합니다.
퀸즐랜드 대학교의 통계학, 데이터 과학, 머신러닝 연구원인 난 예와 함께 일하며, 윌튼은 분류 작업에서 노이즈에 강한 손실 함수를 만드는 프레임워크를 구축했습니다. 여기서 문제는 잘못된 라벨링으로 요약될 수 있습니다. 예를 들어, 개를 고양이로 잘못 라벨링한 훈련 데이터가 있다면, 이는 머신러닝에서 흔한 문제라고 예는 말합니다. “손실 함수가 이런 종류의 노이즈에 강하지 않다면, 모델이 데이터의 규칙성이 아니라 노이즈에 맞추도록 유도할 수 있습니다.”
윌튼은 결정 트리라는 머신러닝 구조에 대한 손실 함수로 시작했습니다. 결정 트리는 예를 들어, 다양한 의료 정보를 분석하여 질병 진단을 내리는 데 사용할 수 있습니다. 이제 윌튼은 신경망 구조에 대한 동등한 함수를 개발하려고 노력하고 있습니다. 결정 트리는 “정말로 다재다능하다”고 그는 설명합니다. “하지만 신경망은 수십만 개 또는 수백만 개의 유사한 유형의 데이터를 수집하는 상황에서 특히 유용합니다.” 지금까지 결과는 유망하다고 그는 말합니다.
노이즈를 이해하는 것 외에도, 전문가들은 ‘도메인 지식’을 통합하는 것이 중요하다고 조언합니다. 실제 세계의 전문가가 시스템에 대해 알고 있는 것을 반영하는 손실 함수를 만들도록 노력해야 합니다. 니우의 손실 함수가 성공한 이유는 니우가 “실제 사용자가 필요로 하는 것에 주의를 기울이고, 이를 가장 잘 작동하게 하는 방법을 찾았기 때문입니다”라고 라즈는 말합니다.
엥겔도 동의합니다. “많은 새로운 AI 과학자들이 도메인 지식이 부족한 문제나 데이터 세트에 투입되는 것을 보고 있습니다,”라고 그는 말합니다. “이 경우, 그들은 도메인 전문가와 오랫동안 앉아 해당 분야를 제대로 이해하고 용어를 해체해야 합니다.” 그는 몇 번의 반복이 필요할 수 있지만, 그 노력은 가치가 있다고 말합니다.
손실 함수의 선택이 점점 더 복잡해질 수 있지만, 프로그래밍 라이브러리인 PyTorch와 scikit-learn은 연구자들이 손실 함수를 비교적 쉽게 바꿀 수 있도록 합니다. 보스만은 여러 함수를 시도해보는 것을 권장합니다. “보통 제 추천은 몇 가지 옵션을 시도해보고, 각각 30번 정도 훈련한 후에 통계적으로 어느 것이 평균적으로 더 나은지 알아보는 것입니다,”라고 그녀는 말합니다.
하지만 이 문제는 곧 더 쉬워질 수 있습니다. 윌튼은 결정 트리를 위한 손실 함수 라이브러리를 관리하고 있으며, 손실 함수의 통합, 즉 다양한 데이터와 문제에 광범위하게 작동하는 포괄적인 방법이 한 가지 가능성이라고 말합니다. 또 다른 옵션은 자신만의 손실 함수를 선택하고 최적화하는 머신러닝 알고리즘입니다. 보스만이 말하는 ‘메타 모델’은 사용 가능한 옵션 목록에서 문제에 가장 적합한 손실 함수를 추천할 수 있습니다.
니우는 더 급진적인 아이디어를 상상합니다. 당신이 연구에 대해 생성형 AI에게 이야기하면, 그것이 올바른 도구를 추천해줄 것입니다. “생성형 AI 모델이 이를 무료로 제공할 수도 있습니다,”라고 그는 제안합니다.
일부 연구자들은 이미 이렇게 하고 있습니다. 멕시코시티에 있는 국립 폴리테크닉 연구소의 머신러닝 연구원인 후안 테르벤은 손실 함수 요구 사항에 대해 정기적으로 챗봇 ChatGPT와 대화합니다. “당신의 문제의 본질과 데이터의 본질을 명확히 해야 하지만, 그것은 시도할 여러 가지를 제안해줄 것입니다,”라고 그는 말합니다. 지난해 테르벤과 그의 동료들은 손실 함수와 그 응용에 대한 광범위한 리뷰를 진행했고, ChatGPT의 손실 함수 선택 능력에 깊은 인상을 받았습니다.
결국, 예는 말합니다. “당신의 문제에 가장 적합한 손실 함수를 찾는 것은 과학이자 예술입니다.” 과학인 이유는 손실 함수를 정량화하고 비교할 수 있기 때문이고, 예술인 이유는 수학과 도메인 지식을 결합하는 것이 종종 창의적인 사고를 요구하기 때문입니다. 그러나 예술이든 과학이든, 손실 함수는 주목할 가치가 있습니다. 이를 무시하면 AI는 여전히 검은 상자처럼 남아 있을 것입니다.”
https://doi.org/10.1038/d41586-024-02185-z
실제 사례 분석
의료 영상 분석에서의 손실함수 최적화 사례를 살펴보겠습니다. 2018년 Nature Medicine에 게재된 “De novo-designed near-infrared absorbing peptide-coated gold nanoparticles enable in vivo photoacoustic tumor imaging” 연구에서는 종양 검출을 위한 딥러닝 모델을 개발했습니다.
초기에는 일반적인 이진 교차 엔트로피 손실함수를 사용했으나, 작은 종양을 놓치는 문제가 발생했습니다. 연구팀은 focal loss라는 변형된 손실함수를 도입했습니다. 이 손실함수는 쉬운 예제보다 어려운 예제에 더 큰 가중치를 부여합니다.
focal loss 도입 결과, 모델의 종양 검출 정확도가 기존 82%에서 91%로 크게 향상되었습니다. 특히 작은 크기의 종양 검출률이 2배 이상 증가했습니다.
또 다른 사례로, 자연어 처리 분야의 연구를 들 수 있습니다. 2019년 ACL 컨퍼런스에서 발표된 “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” 논문에서는 새로운 손실함수를 제안했습니다.
기존의 언어 모델은 다음 단어를 예측하는 단방향 학습만 수행했습니다. BERT는 양방향 학습을 위해 Masked Language Model(MLM)이라는 새로운 손실함수를 도입했습니다. MLM은 문장의 일부 단어를 가리고, 모델이 이를 예측하도록 합니다.
이 혁신적인 접근 방식 덕분에 BERT는 11개의 자연어 처리 태스크에서 최고 성능을 달성했습니다. 특히 질문 답변 태스크에서는 인간 수준의 성능을 보였습니다.
손실함수 최적화의 실제 응용
금융 분야에서도 손실함수 최적화가 중요하게 적용되고 있습니다. 2020년 Journal of Financial Economics에 발표된 “Machine Learning for Stock Selection” 연구에서는 포트폴리오 최적화를 위한 새로운 손실함수를 제안했습니다.
연구팀은 전통적인 평균-분산 최적화 대신, 샤프 비율을 직접 최적화하는 손실함수를 개발했습니다. 이 접근법은 5년간의 백테스트에서 기존 방식보다 20% 높은 수익률을 달성했습니다.
또한 강화학습 분야에서도 손실함수 최적화가 주목받고 있습니다. DeepMind가 2021년 Nature에 발표한 “Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model” 연구에서는 MuZero라는 알고리즘을 소개했습니다.
MuZero는 복잡한 게임 환경에서 모델 기반 계획과 모델 프리 강화학습을 결합합니다. 이를 위해 여러 손실함수를 동시에 최적화하는 멀티태스크 학습 방식을 채택했습니다. 그 결과 Atari 게임부터 바둑까지 다양한 도메인에서 최고 수준의 성능을 보였습니다.
이러한 사례들은 적절한 손실함수의 선택과 최적화가 AI 모델의 성능을 크게 향상시킬 수 있음을 보여줍니다.
결론
요약 및 주요 포인트
본 글에서는 AI, 특히 머신러닝과 딥러닝에서 손실함수의 중요성과 그 응용에 대해 살펴보았습니다. 주요 포인트를 요약하면 다음과 같습니다:
손실함수는 모델의 예측과 실제 값의 차이를 수치화하여 모델의 성능을 평가하고 개선하는 핵심 요소입니다.
회귀 분석, 분류 문제 등 다양한 문제 유형에 따라 적합한 손실함수가 다릅니다.
손실함수의 미분은 모델 파라미터 최적화를 위한 경사 하강법의 기초가 됩니다.
경사하강법의 다양한 변형과 최적화 기법들은 손실함수를 효과적으로 최소화하기 위해 개발되었습니다.
손실함수의 그래프를 통해 학습 과정을 시각화하고 모델의 성능을 진단할 수 있습니다.
실제 사례에서 볼 수 있듯이, 적절한 손실함수의 선택과 최적화는 모델의 성능을 크게 향상시킬 수 있습니다.
연구 방향
손실함수는 AI 연구의 핵심 주제로 계속해서 주목받을 것으로 예상됩니다. 앞으로의 연구 방향은 다음과 같이 전망됩니다:
복합적인 목표를 달성하기 위한 다중 손실함수의 효과적인 결합 방법에 대한 연구가 활발해질 것입니다. 2022년 ICML 컨퍼런스에서 발표된 “Multi-Task Learning as Multi-Objective Optimization” 논문은 이러한 트렌드를 잘 보여줍니다.
불확실성을 고려한 확률적 손실함수에 대한 연구가 증가할 것으로 예상됩니다. 베이지안 딥러닝 분야에서 이미 이러한 움직임이 보이고 있습니다.
적대적 공격에 강건한 손실함수 개발이 중요해질 것입니다. 2021년 ICLR에서 발표된 “Adversarial Robustness Through Local Linearization” 연구는 이 방향의 선구적인 예시입니다.
설명 가능한 AI를 위한 해석 가능한 손실함수 설계가 주목받을 것입니다. 이는 AI 시스템의 의사결정 과정을 이해하고 신뢰성을 높이는 데 중요합니다.
양자 컴퓨팅의 발전과 함께, 양자 알고리즘에 적합한 새로운 형태의 손실함수 연구가 시작될 것으로 예상됩니다.
결론적으로, 손실함수는 AI 시스템의 성능과 신뢰성을 결정짓는 핵심 요소로, 앞으로도 지속적인 연구와 혁신이 이루어질 것입니다. 이를 통해 AI가 더욱 정확하고, 효율적이며, 신뢰할 수 있는 기술로 발전할 수 있을 것입니다.